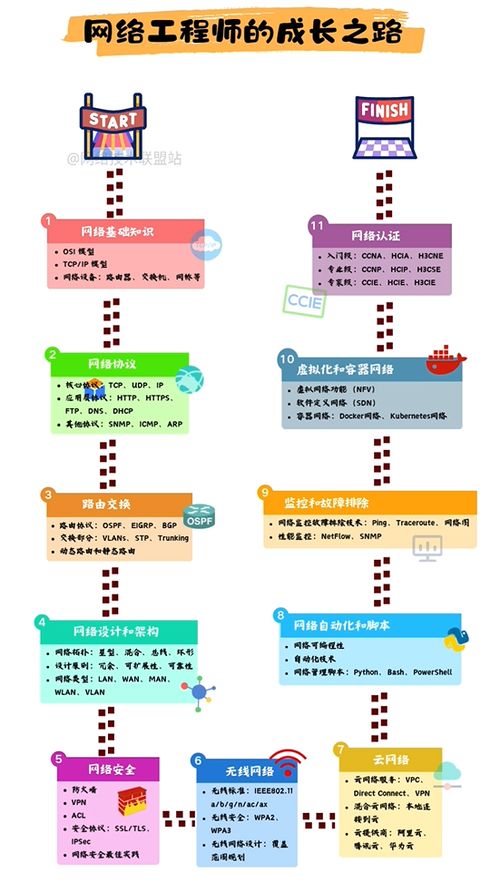
在當今這個萬物互聯的時代,網絡如同社會的神經系統,而網絡工程師則是這一系統的構建者與維護者。從最初懵懂地連接一根網線,到后來規劃、部署、優化覆蓋全球的復雜網絡,成為一名卓越的網絡工程師,是一條充滿挑戰與成就感的成長之路。本指南旨在為你勾勒出一條清晰的進階路徑,助你從零基礎起步,逐步邁向技術大牛的行列。
第一階段:筑基——夯實理論基礎與入門技能(0-6個月)
一切偉大的構建皆始于穩固的基石。對于網絡工程而言,這個基石就是計算機網絡的核心原理。
- 核心知識學習:
- 計算機網絡體系結構:深入理解OSI七層模型和TCP/IP四層模型,這是理解所有網絡通信的“世界地圖”。
- 關鍵協議:掌握IP地址(IPv4/IPv6)、子網劃分、路由協議(如靜態路由、RIP、OSPF)、TCP/UDP協議等。書籍如《計算機網絡:自頂向下方法》或《TCP/IP詳解 卷一》是經典之選。
- 網絡設備初識:了解交換機、路由器、防火墻等基礎網絡設備的功能與區別。
- 實踐入門:
- 利用模擬器軟件(如Cisco Packet Tracer, GNS3, Eve-NG)搭建簡單的實驗環境,完成VLAN劃分、靜態路由配置等基礎實驗。動手是理解理論的最佳途徑。
- 考取入門級認證,如思科的CCNA或華為的HCIA。備考過程能系統化地梳理知識體系,其認證本身也是求職時的有力敲門磚。
第二階段:拓疆——掌握主流技術與工程實踐(6-18個月)
在打好基礎后,需要將知識擴展到企業級網絡所需的各項主流技術。
- 核心技術深化:
- 交換技術:深入掌握STP、以太通道、VTP等高級交換技術。
- 路由技術:熟練配置與排錯OSPF、EIGRP(思科體系)、BGP等高級路由協議。
- 網絡安全基礎:學習ACL、NAT、防火墻基本原理、VPN(如IPSec、SSL VPN)技術。
- 網絡服務:理解并實踐DHCP、DNS、NTP等關鍵服務的部署。
- 實踐與認證:
- 在模擬器或真機環境中,獨立設計并實現一個中小型企業網絡的完整方案,包括拓撲設計、地址規劃、設備配置與連通性測試。
- 向專業級認證邁進,如思科的CCNP Enterprise或華為的HCIP-Datacom。這一階段的認證學習將使你的知識體系從“知道”升級到“精通”。
第三階段:專精——選擇方向并深入前沿領域(18-36個月及以上)
網絡工程領域廣闊,成為“大牛”往往需要在某一細分領域達到專家水準。
- 方向選擇與深耕:根據興趣與行業趨勢,選擇一個或多個方向進行深度鉆研:
- 數據中心網絡:聚焦于FabricPath、VXLAN、SDN、自動化運維等技術。
- 網絡安全:向網絡安全專家發展,深入學習防火墻高級策略、入侵檢測/防御、安全審計、態勢感知等。
- 運營商網絡:深入研究MPLS、Segment Routing、網絡虛擬化、5G承載網等廣域網技術。
- 無線網絡:精通企業級WLAN設計、部署、優化與安全,如思科的無線控制器技術。
- 自動化與編程:這是現代網絡工程師的“超能力”。學習Python、Ansible等工具,實現網絡配置、監控、運維的自動化,向“網絡開發工程師”演進。
- 專家級認證與項目歷練:
- 挑戰專家級認證,如思科的CCIE或華為的HCIE。這不僅是對技術的終極考驗,更是毅力與解決問題能力的證明。
- 參與或主導大型、復雜的實際網絡項目。真正的技術大牛是在解決一個又一個棘手故障、完成一項又一項艱巨工程中錘煉出來的。
貫穿始終的“軟實力”與習慣
技術之路,硬實力是刀鋒,軟實力則是揮舞刀鋒的手臂。
- 持續學習能力:網絡技術日新月異,保持好奇心,定期閱讀技術博客、關注行業動態、參與技術社區是必須的。
- 文檔能力:清晰的拓撲圖、規范的配置文檔、詳盡的故障報告是專業工程師的標配。
- 溝通與協作能力:網絡工程絕非孤軍奮戰,你需要與客戶、同事、供應商清晰有效地溝通。
- 邏輯思維與排錯能力:面對網絡故障,建立系統化的排錯思路(如分層法、對比法、替換法)比盲目嘗試更重要。
###
從零基礎到技術大牛的征途,沒有捷徑,但有一張清晰的地圖可以讓你少走彎路。這條路是知識累積的階梯,是無數個小時實驗與排錯的堅持,更是從“連通網絡”到“創造價值”的認知飛躍。記住,每一個復雜的網絡都是由最簡單的協議和配置構建而成。今天,就從認識第一個IP地址開始,開啟你的網絡工程師成長之旅吧。